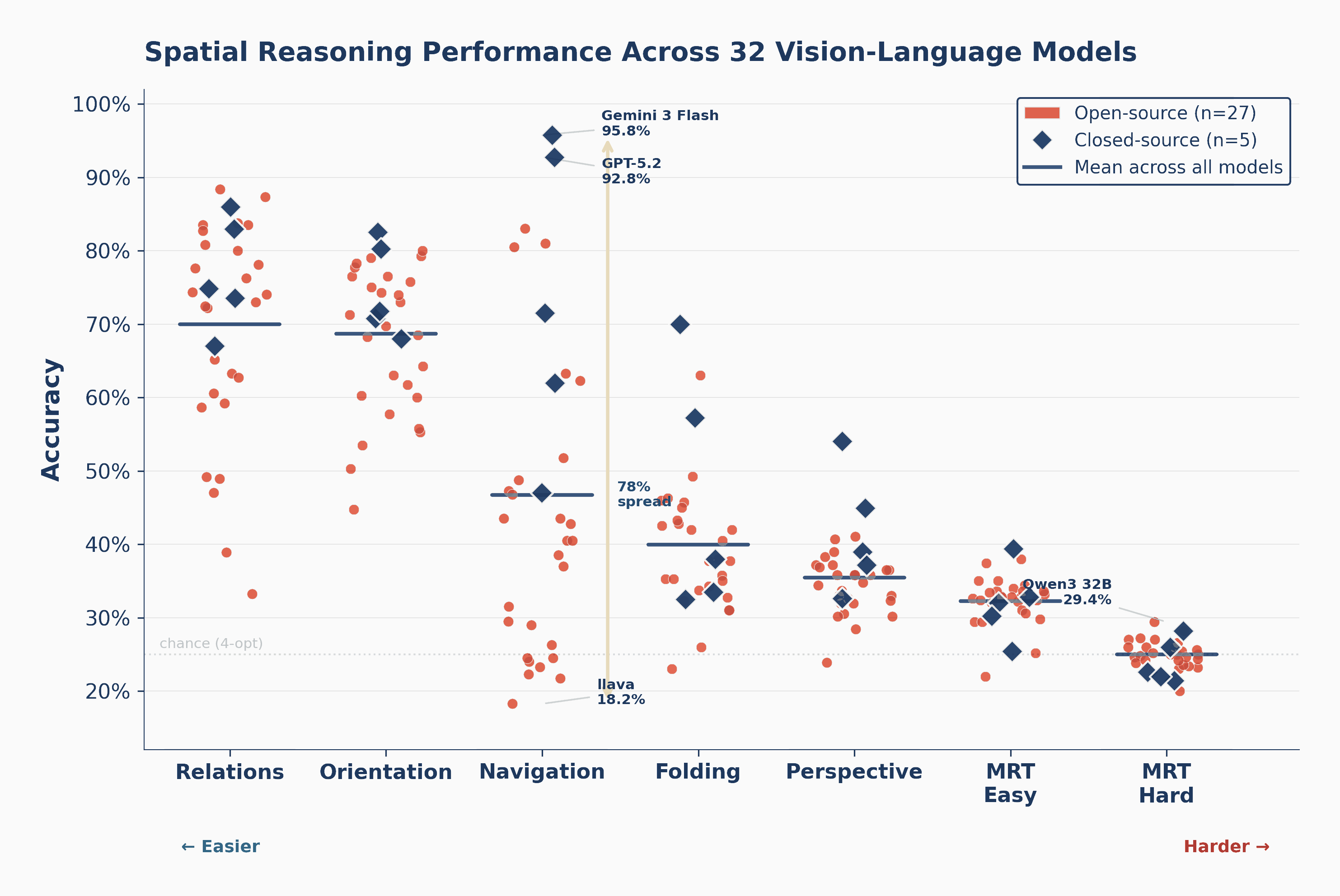
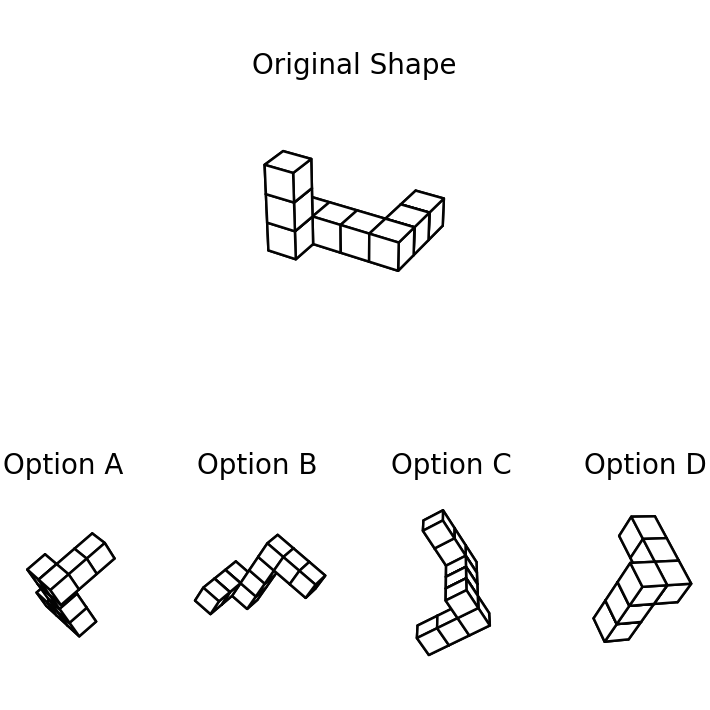
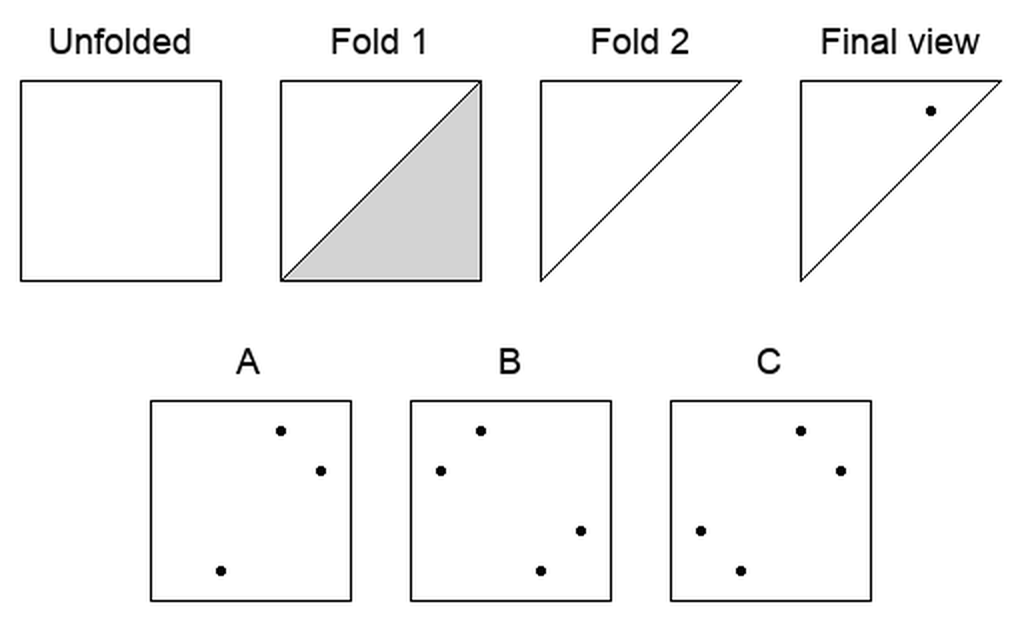
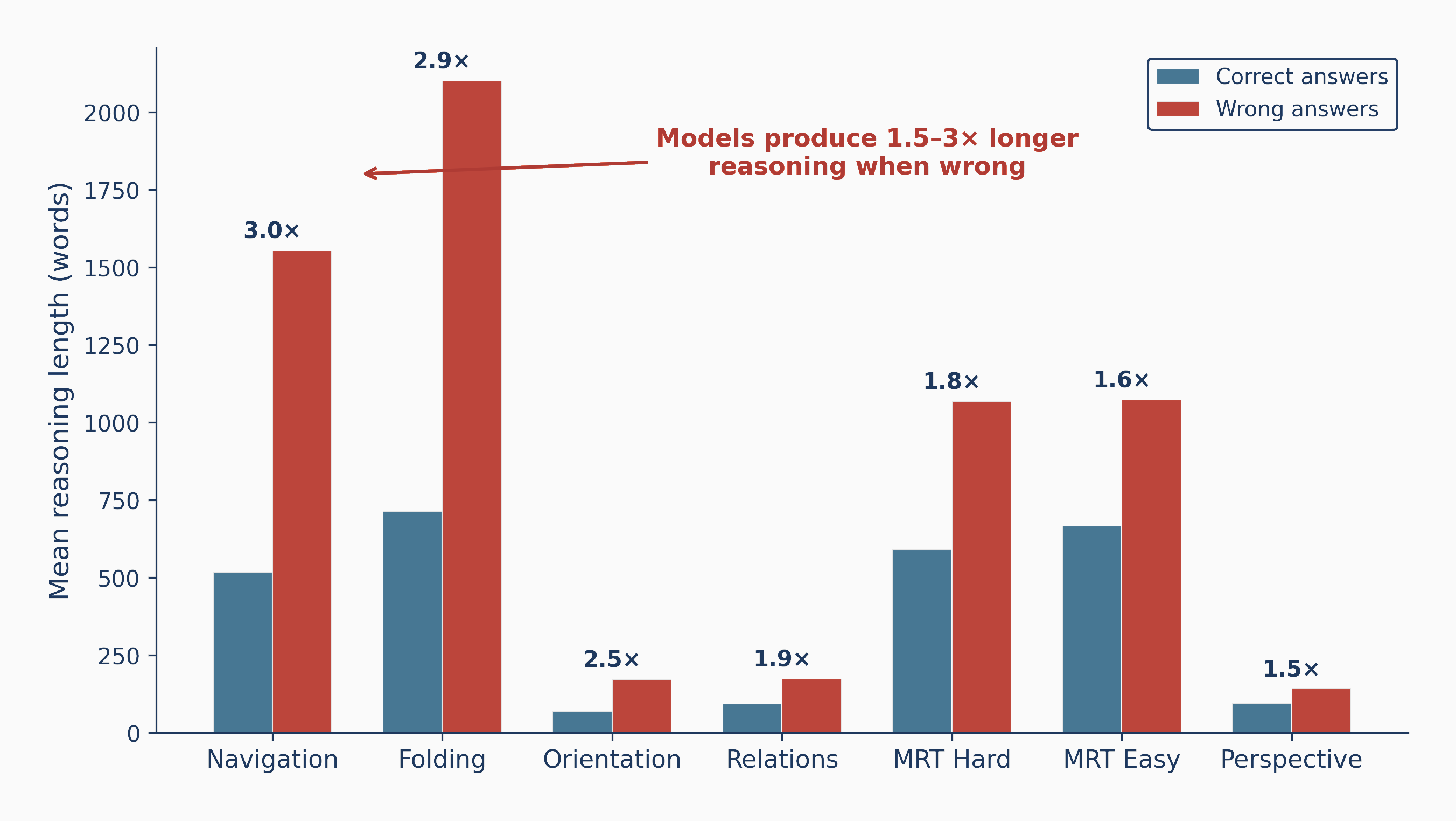
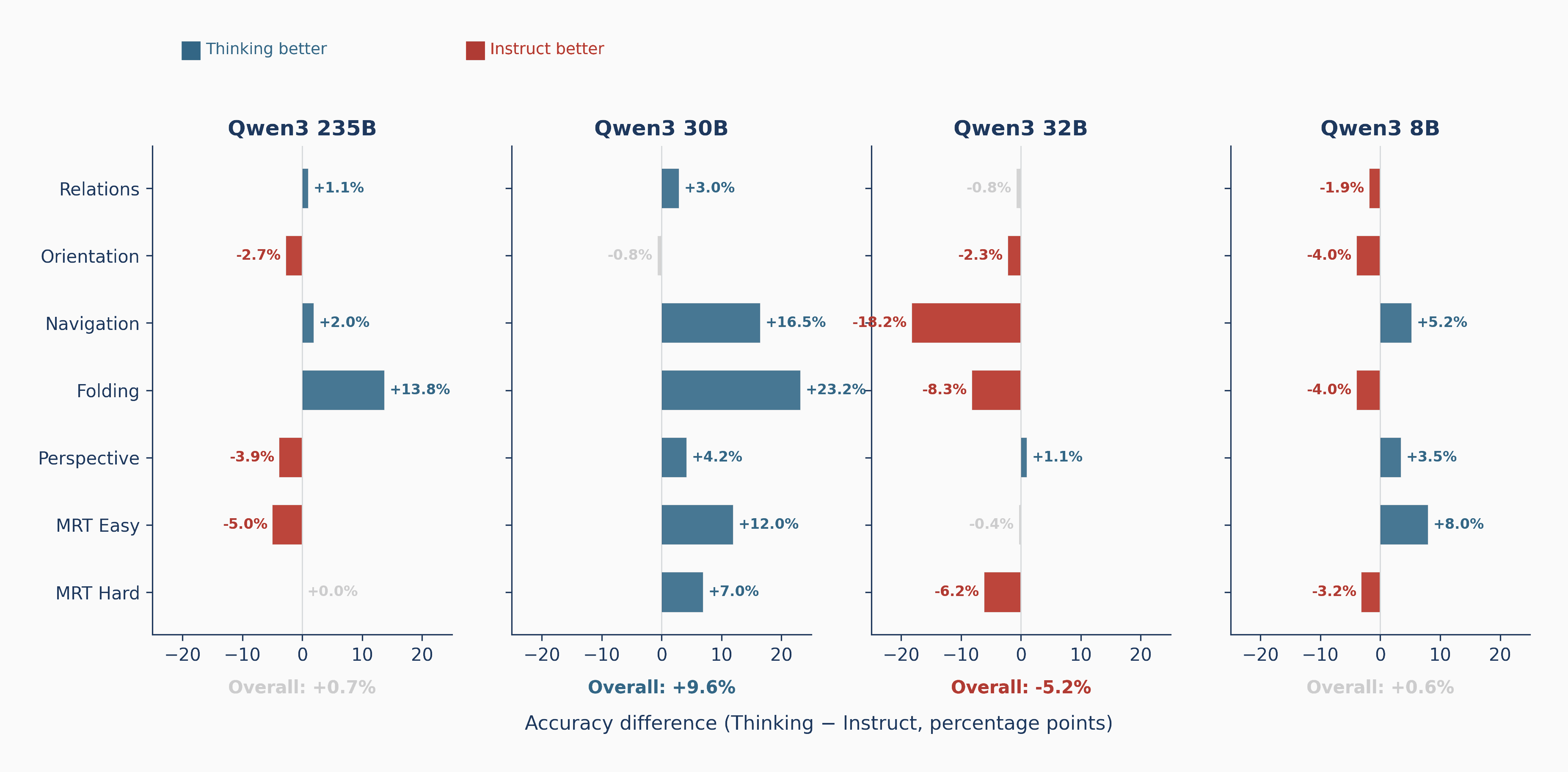
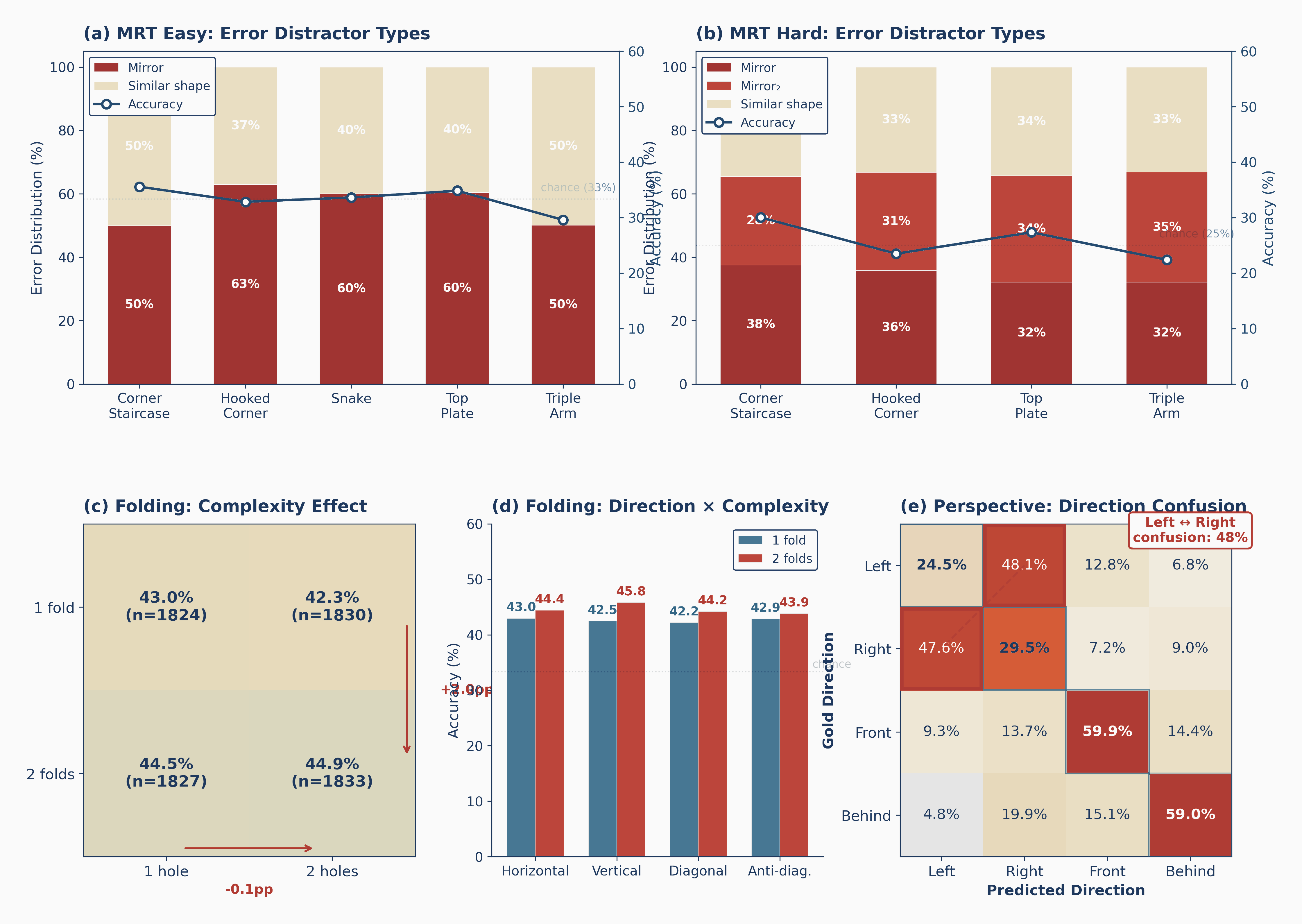
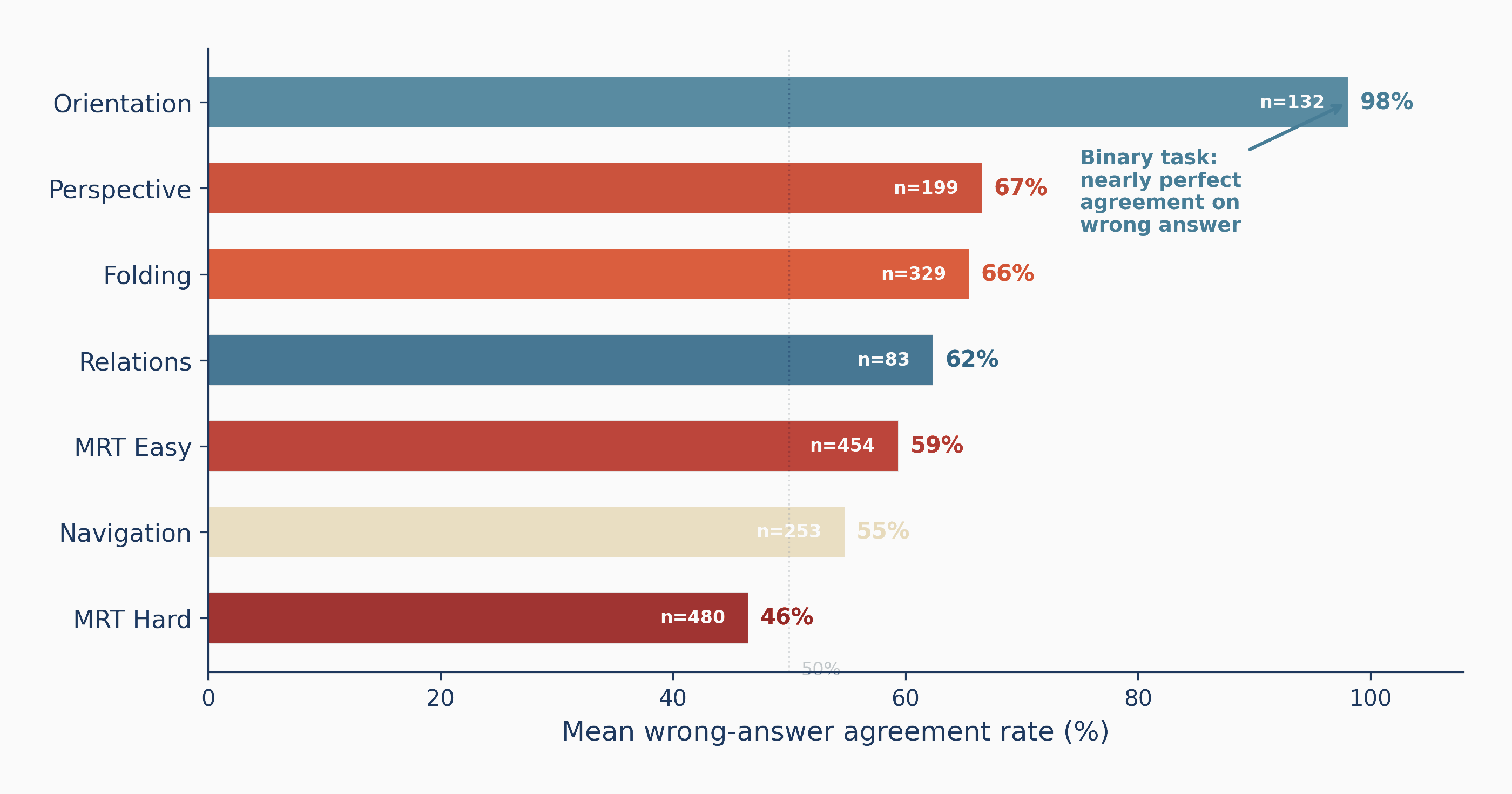
The headline
Strong at seeing, near-chance at simulating
Across seven tasks, the same 32 models that describe scenes well collapse toward chance once a task demands mental transformation, with 3D mental rotation bottoming out at chance. The gap is not gradual; it is a cliff.